 2016, Vol. 48
2016, Vol. 48



近些年来,随着社会需求和科学工程技术的进步,视觉目标跟踪(video tracking)已经被应用到很多的领域,如:视频监控、车辆导航和人机交互等[1].但是当跟踪图像存在背景杂波、图像噪声(如图像遮挡、图像快速移动)时,很多算法都未能取得很好的图像追踪效果.
矩阵的稀疏表示(sparse representation), 又称压缩传感(compressive sensing)[2],是一种先把图像数据矩阵化,然后利用其内在稀疏性和矩阵线性表示来进行处理的技术,它可以显著地提高运算效率.在稀疏表示、压缩感知理论兴起后,相关的理论很快地被应用到跟踪领域[3-7].如文献[6]提出了基于L1范数最小化的目标跟踪方法(L1-tracker),该方法利用粒子滤波器框架下的稀疏近似方法来解决视频跟踪问题,在解决图像遮挡、强烈的光照变化和姿态变化等情况取得了较好的效果,并减少了运算的复杂度.此后作者又重新对文献[6]的方法进行改进[8-9].除了L1-tracker方法外,很多学者也提出了其他的方法,如文献[10]提出了Real-Time Compressive Tracking跟踪方法.
但是当图像中存在复杂图像噪声信号或图像遮挡时,传统的L1-Tracker方法在处理精度和遮挡误判方面还存在一些问题.为解决这些问题,本文在此基础上[8-9, 11-12]进行了一些有效的改进,提出增加拓展模板(固定模板和近况模板)的策略, 实验结果证明加入拓展模板的算法在不破坏算法原有优势的前提下,有效地提升了L1-tracker算法的精度和对遮挡问题的判断能力.
1 传统L1-tracker算法 1.1 L1-tracker模型由文献[6]提出的L1-tracker算法是一种建立在粒子滤波基础上的利用稀疏表示的图像追踪算法.稀疏表示在这里是被用来计算某一候选目标Xk对应的似然值p.在给定追踪目标的特征模板Tk={tk1, tk2, …, tkn}中, Tk的每一列都是一个特征模板.候选目标集合为Xk={xk1, xk2, …, xkN},候选目标对应的图像Yk={yk1, yk2, …, ykN}存在以下关系
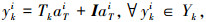
|
(1) |
式中I的每个列向量是一个点模板.点模板主要用于应对噪音、非目标图像以及拟合图像与实际图像的个别偏差.稀疏表达的系数aki=[aTi; aIi]是稀疏的,除其部分维度为1外,大多数维度都为零或者接近为零.式(1)在一定程度上很好地表达了稀疏表示的核心思想,即将追踪目标用特征模板和点模板来线性表示.但是这个表达式只有当前图像和目标接近时,才能只使用部分特征模板来很好地拟合出图像;而当图像与目标差别很大时,就不得不更多地使用多种特征模板和点模板来拟合目标图像,进而导致运算的复杂程度变高.所以为了避免这种情况的出现,在文献[6]中对表示式进行限制为
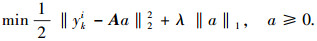
|
(2) |
式中:A=[TkI-I]; λ‖a‖1直观地反映了上述提到的性质,即希望尽量使用较少的模板; 而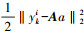
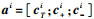
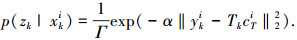
|
(3) |
式中:Γ为归一化因子;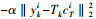
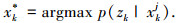
|
基于模板的跟踪方法最早是在文献[7]中被提出的.文献[14]通过固定的模板来进行追踪,并使追踪结果和模板的距离平方和最小化.一般而言,追踪目标只会在相对局部的图像帧里保持不变,随着图像序列的变化,追踪目标将不可避免地发生变化,最后导致原有模板难以继续进行准确的追踪.换句话说,如果不对模板进行更新,由于各种光照或者位置变化导致的目标改变将使传统L1-tracker追踪算法失效.另一方面,如果过于频繁、随意地进行模板更新,模板将不断地累积一些不属于目标特征的内容,最后导致模板失效.所以,L1-tracker算法需要能动态地应对目标变化,并进行模板的更新.文献[5]通过把衡量两个同规格图像相似程度的方程Sim(., .)定义为Cos(θ)来进行判别,其中θ是将两个输入图像向量化之后的向量角为
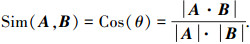
|
模板需要更新,才能很好地应对追踪目标的变化,进而保持较好的追踪效果.虽然上述更新方法考虑到检测模板的更新需求,以及如何选择合适的模板来进行更新,但是它没有考虑到目标可能被其他物体遮挡的情况.当这种情况发生时,大量不是目标特征的内容会被添加进特征模板,最终导致误识别事件的发生.
所以在传统的L1-tracker算法中,使用了两种模板:一种是特征模板,另一种是点模板.特征模板反映了追踪目标的图像特征,点模板则对应遮挡、采集到的非目标图像以及噪声信号的检测.虽然点模板,主要用于遮挡和噪声检测,但在进行目标跟踪时,目标的正常外表变化也会使用点模板,但是这时的使用和遮挡还是有区别的;遮挡时通常是成片的,而普通外表变化是渐进的、相对零散的.通过对点模板矩阵的分析可知,如果对上面得到的0、1二值矩阵进行形态学处理,从去掉一些小孔洞之后的图像来看,遮挡会导致大片的黑色区域(数值为1),而一般的外表变化则只会出现比较零散的黑色区域.因此就可以通过计算图像中的最大黑色联通区域来判断是否发生了遮挡,如果这个区域大于图像总面积的某个比例,就可以认为出现了遮挡.在出现遮挡之后,本文可以暂时(如文献[5]使用的维持5帧)停止模板的更新.
2 改进的L1-tracker算法通过对传统L1-tracker算法的分析,本文知道在传统L1-tracker算法[9, 11-12]中,进行模板更新之前需要进行遮挡的检测.遮挡的检测需要将点模板的系数a=[cT; cI]向量转化为和模板同规格的矩阵,然后按照一定的预设值将其转化为0、1的二值矩阵,再在这个矩阵上检测最大的联通区域,看是否构成遮蔽判断.但是在传统L1-tracker算法中cT和cI存在一些混淆.cT有大于0的限制,但是cI没有,而且传统L1-tracker算法只考虑了cT>0的情况,也就说只是将系数0、1二值矩阵中大于预设值的部分转化了1.而当遮蔽物的灰度值是小于当前的追踪目标时,传统L1-tracker算法将不进行处理.所以这个做法并不十分合适.
本文针对这个问题,对传统L1-tracker算法进行改进.分开考虑模板系数为正和为负的情况,并在特征模板和点模板的基础上,加入了拓展模板(固定模板和近况模板).这种实现称之为tracker-2.由上述分析可以知道,传统的L1-tracker算法是介于频繁更新模板和不更新模板两种策略之间的一种动态策略,而固定模板和近况模板相当于这两种极端策略.
2.1 固定模板在进行目标追踪时,不时会出现一种极端的情况,即追踪目标暂时性地从图像序列中消失.如果不考虑这种变化往往会导致算法对追踪目标消失的应对能力变弱,并且在追踪目标再次出现后也无法进行有效地判断.因为在当前追踪的图像中不存在目标时,它会和追踪算法中的目标模板出现很大的差异,此时算法可能会将这种情况视为目标已经发生改变、而目标模板不能很好地应对目标的变化,所以会尝试根据当前错误的追踪结果来更新模板,进而导致追踪模板被加入一些错误的特征,最后出现识别目标的偏移.所以当前的许多图像追踪算法都会选择检测目标是否在当前帧中出现,来决定下一步图像追踪的走向,如果检测到目标不存在,就会停止追踪,直到再次检测到目标后再继续进行跟踪.传统L1-tracker算法应对这种目标消失的情况具有一些天然优势.对于目标消失,传统L1-tracker算法并不停止进行追踪,而是继续追踪.这个时候由于追踪的结果会与原本的追踪目标产生很大差异,所以会大量使用点模板,这样在点模板的系数矩阵二值化之后,就会形成面积较大的联通区域,进而可以判断出现了遮挡,然后就会停止模板的更新,提高对目标变化的鲁棒性.
但是大量使用点模板会带来运算量的增加,所以为解决该问题,本文提出一种应对策略—加入固定模板,固定模板将最初指定的目标保存下来,单独制作成一个固定不变的模板,它不会因模板更新策略而被更新[15].这样做的依据是:当目标消失时,特征模板可能已被错误地更新过,已经不能很好地描述目标的图像特征;此外当目标再次出现时,其图像特征也是难以预测的,所以采用最原始的目标模板是一种保守而且有效的策略.对于没有出现目标消失的情况而言,新添加固定模板也不会有负面影响,这是因为固定模板保持了追踪目标最初的图像特征,不会引进任何错误的结果.所以增加固定模板是一种保守且不会对追踪准确度有负面影响的策略,最多只是线性地增加了少量的运算时间.
2.2 近况模板如固定模板所述,在使用传统L1-tracker算法进行目标跟踪时,会出现因发生遮挡而造成误识的现象.这种问题的发生是因为模板不能很好地描述当前的追踪,即在需要更新模板时,不去更新模板,反而减少点模板的使用,从而严重影响跟踪的效果.
针对此问题,本文提出一种应对策略—加入近况模板.近况模板,就是根据相似度大小,从最近的跟踪结果中(与文献[5]相同,本文也选择为5帧)挑选一个与特征模板描述程度最高的追踪结果,并加入到模板中,然后不断地以最新的、可靠性高的追踪结果对其进行更新.这种策略来源于这样一种认识:图像模板的变化在相对局部的范围内是有限的,并且大的图像变化来源于多次较小变化的积累.同时近况模板作为一个非常可靠的追踪结果.它具有两个重要的性质,首先它是可靠的,基本上能够肯定是本文追踪的目标,否则它不具有作为模板的资格;其次它是近况的,是距离当前帧较近的一次识别结果,从而当前目标与它的差异程度要小于当前目标和特征模板的差异.
本文提到的一个误识遮挡的典型场景是当开始出现小的外观变化时,传统L1-tracker算法还认为模板足以描述当前追踪的结果,而不进行模板的更新(如果轻易更新,容易在模板上积累错误的特征,造成追踪结果的偏移);但是随着目标逐渐发生变化,最终的结果是当传统L1-tracker算法发现模板已经不能很好地描述当前的追踪结果时,会使用很多的点模板,进而容易在系数矩阵二值化之后,出现成片的1-联通区域,然后错误的识别为遮挡.而本文采用近况模板(近况矩阵)策略后,在目标发生小的外观变化时,tracker-2算法能够发现它虽然有些小的不同,但还是可以信任的,这样就能将这样小的目标变化提前保留下来,不会放任它一直积累;等发现需要更新模板时,就不需要大量地使用点模板,因为这些模板的变化已经被近况模板描述了,从而减少了因遮挡而发生的错误判定.
3 结果分析在实验中,tracker-2方法采用Matlab实现,实验系统平台是Windows7.在具体的参数设置上,判定式Sim的预设阈值τ=0.3,超过0.3时则认为模板已经不能很好地描述当前的追踪结果;特征模板的数目为10, 使用的粒子数目为600, λ=0.01,μt=10.进行对比实验的传统L1-tracker算法也使用同样的设置.
3.1 结果对比分析在量化测试中,本文选择了4个公开的标准视频, 对加入拓展模板后的优化L1-tracker (tracker-2)算法与传统的L1-tracker算法进行对比测试.在性能评价上,文献[10, 15-16]通过选取区域交叠率[17]来决定每一帧的追踪结果是否可以接受.具体描述为跟踪目标区域与实际目标区域的交叠率:两区域之交的面积与两区域之并的面积比.设某一帧跟踪目标区域为ROIT,实际目标区域为ROIG,则该帧的交叠率score可计算为
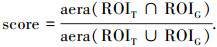
|
当交叠率小于50%,则认为该帧跟踪失败,进而可定义所有帧的正确率,即正确跟踪的帧数与总帧数之比,设总帧数为Ntotal,正确跟踪的帧数为Nscore≥0.5,整体跟踪正确率P为
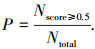
|
为了能更进一步的理解,本文将二者在对应图像帧中的追踪结果与标准目标位置的中心矩进行对比, 如图 1~4所示.

|
图 1 Car测试结果对比 |

|
图 2 Singer测试结果对比 |

|
图 3 Walking测试结果对比 |

|
图 4 Face测试结果对比 |
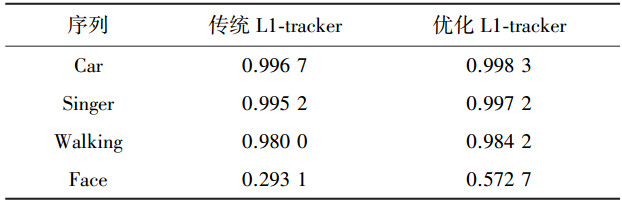
优化L1-tracker算法和传统L1-tracker算法的处理正确率的对比结果见表 1.通过对比测试结果,本文可以发现在Car、Singer、Walking这3个数据集中,传统的L1-tracker和优化L1-tracker(tracker2)几乎没有大的差别,这说明本文的改动不会破坏传统L1-tracker本身具有的一些优势,没有降低追踪效果,甚至还有部分的提升.而在Face数据集中,本文优化的L1-tracker相对于传统L1-tracker有了非常显著的提升,几乎将整体的正确率翻倍.综上所述,通过对4个测试集处理结果的分析可以看出,本文的方法在不破坏传统L1-tracker优势的基础上,实现了进一步的性能提升.
| 表 1 两种方法处理正确率的对比 |
通过对图 1的分析,可以发现在多数时刻,优化L1-tracker算法比传统L1-tracker算法的目标中心矩差要小,也就说,在满足基本追踪要求的基础上,优化L1-tracker能够更加准确地进行跟踪.通过对图 1分析可以看出,虽然本文的优化L1-tracker在总体数据上略微好一些.但在特定应用场景上,即光亮噪声特别严重的时候,由于优化L1-tracker的近况模板会比较及时地进行更新,所以会积累一部分的光噪信息,进而影响识别.
在图 3的Walking数据集中,对于测试视频在200帧左右时,优化、传统的L1-tracker都出现了识别追踪的偏移,此后各帧的跟踪结果又回到了正常的追踪水平上.这是因为在Walking测试视频的200帧左右时,本文追踪的主要目标被另外一个行人挡住了绝大部分.这样的遮挡不可避免的会引起追踪的偏移,而L1-tracker本身非常良好的遮挡识别使其在之后的图像帧中,又能继续识别和追踪目标,而不是在遮挡的时候出现模板劣化,进而导致无法继续追踪.本文提出的优化L1-tracker一方面比传统L1-tracker更先出现偏移,同时也更先回到正常的追踪.通过结果分析, 本文得到以下结论,一方面优化L1-tracker会有更严格的遮挡判定,所以很快就检查到了遮挡,允许大量使用点模板,进而导致偏移很快就出现;另一方面,近况模板也加速了检测到一个合适的追踪结果,所以能够快速地回到正确追踪的节奏中.
在图 4中,可以发现优化L1-tracker在测试中出现压倒性的优势.在Face数据集中频繁地出现目标被遮挡和各种目标形变,此时优化L1-tracker具有更严格的遮挡判断,避免了识别误差的积累;同时由于近况模板的使用,可以使算法避免将目标变化识别为遮挡,从而能够及时地响应形变,正确地更新模板.这样在图像受遮挡导致偏移之后,优化L1-tracker能很快地重新回到正确的追踪状态.相比之下,在大多数情况下,传统的L1-tracker算法表现的性能较优化L1-tracker算法差,同时传统L1-tracker算法的曲线相对更加平滑(体现出错误不断积累的过程);而优化L1-tracker的曲线不平滑(体现了L1-tracker对于追踪状态的不断检验),并能及时地采取正确地应对策略.在总体的测试结果上也实现了大幅度地提升.
3.2 图像对比分析本文将一些图像帧和追踪到的图像进行直观比较,通过视觉图像对比,直观地体现本文新策略的效果.在图 5, 6的各个子图中,最左边是初始标定帧,其后分别是不同时刻的识别效果图,方框选中的部分是L1-tracker的跟踪结果.

|
图 5 优化、传统的L1-tracker在Face上的对比 |

|
图 6 测试集上的直观追踪图像 |
在图 5中,本文对优化、传统的L1-tracker结果进行了直观地对比.在Face序列中,随着大量遮挡的出现、使追踪目标交替变化出现,这大大影响了跟踪的准确性.在图 5(b)中,传统L1-tracker算法从目标人的头发生偏转开始,识别结果就出现了明显地偏移;而在图 5(a)中,优化L1-tracker(tracker-2)算法则能够基本完成追踪任务,没有出现明显的偏差.尤其是在跟踪的后期,虽然优化L1-tracker的追踪目标框已经变得相对很小,但是它的位置还是很准确.这种对比说明优化L1-tracker算法应对遮挡的能力较传统L1-tracker算法有了极大地提升.
在图 6的测试图像中,图 6(a)所示测试集Car的视频主要是检测光线变暗和位置变化带来的目标跟踪问题.图 6(b)所示测试集Singer的视频则具有更强的光照,甚至能够掩盖目标的轮廓.在这两个测试集中,需要注意的是在光线变化时,能否及时地更新模板响应目标的变化.在图 6 (a)中可以发现本文追踪的目标车辆,在入桥洞和出桥洞的时候都进行了模板更新;入桥洞更新是响应光影变化;但是出桥洞的更新原因,其实是容易被忽略的,因为出洞的时候似乎与入洞前的图像一样,一些尚未更新的模板似乎也能够描述目标.但是其实Car的测试视频中还是存在很强的光照影响,出洞后和入洞前,目标车辆后玻璃的图像都发生了很大变化,所以两者都需要更新.通过对比,图 6 (b)部分则只在光变强的时候进行了更新,在光变弱的时候没有更新,这说明尚未进行更新的模板还能在光照变弱之后继续识别追踪目标.在两个测试过程中,位置的变化都没有影响到追踪的正常进行.
4 结论1) 通过对基于粒子滤波算法框架和稀疏表示技术的L1-tracker算法进行探讨,完成了对传统L1-tracker图像追踪算法的改进,提出了新的策略-拓展模板(近况模板和固定模板)来应对图像目标追踪中的目标被遮挡和遮挡误判等问题.
2) 在经典图像目标追踪测试集上,本文对改进后的优化L1-tracker算法和传统L1-tracker算法进行比较.对比实验数据有效地证明,加入的拓展模板在不破坏算法的原有优势的前提下,有效地提升了L1-tracker算法的精度和应对遮挡问题的能力.
| [1] |
YILMAZ A, JAVED O, SHAH M. Object tracking:a survey[J]. ACM Computing Surveys, 2006, 38(4): 1-45. |
| [2] |
LI Hanxi, SHEN Chunhua, SHI Qinfeng. Real-time visual tracking using compressive sensing[C]//Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2011: 1305-1312.
|
| [3] |
JIA Xu. Visual tracking via adaptive structural local sparse appearance model[C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Washington, DC: IEEE Computer Society, 2012: 1822-1829.
|
| [4] |
ZHANG Tianzhu, GHANEM B, Liu Si, et al. Low-rank sparse learning for robust visual tracking[C]//Proceedings of the 12th European conference on Computer Vision. Berlin, Heidelberg: Springer-Verlag, 2012: 470-484.
|
| [5] |
ZHONG Wei. Robust object tracking via sparsity-based collaborative model[C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Washington, DC: IEEE Computer Society, 2012: 1838-1845.
|
| [6] |
MEI Xue, LING Haibin. Robust visual tracking using ℓ1 minimization[C]//Proceedings of the 12th International Conference on Computer Vision (ICCV). Kyoto: IEEE, 2009, 1436-1443.
|
| [7] |
LUCAS B D, KANADE T, et al. An iterative image registration technique with an application to stereo vision[C]//Proceedings of the 7th international joint conference on Artificial intelligence. San Francisco, CA: Morgan Kaufmann Publishers Inc, 1981: 674-679.
|
| [8] |
MEI Xue, LING Haibin. Robust visual tracking and vehicle classification via sparse representation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(11): 2259-2272. |
| [9] |
MEI Xue, LING Haibin, WU Yi, et al. Efficient minimum error bounded particle resampling L1-tracker with occlusion detection[J]. IEEE Transactions on Image Processing, 2013, 22(7): 2661-2675. DOI:10.1109/TIP.2013.2255301 |
| [10] |
ZHANG Kaihua, ZHANG Lei, YANG M H. Real-time compressive tracking[C]//Proceedings of the 12th European conference on Computer Vision. Berlin, Heidelberg: Springer-Verlag, 2012: 864-877.
|
| [11] |
BAO Chenglong, Wu Yi, Ling Haibin et al. Real time robust L1-tracker using accelerated proximal gradient approach[C]//Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Washington, DC: IEEE Computer Society, 2012: 1830-1837.
|
| [12] |
MEI Xue, LING Haibin, WU Yi, et al. Minimum error bounded efficient L1-tracker with occlusion detection[C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Providence, RI: IEEE Xplore, 2011: 1257-1264.
|
| [13] |
KIM S J, KOH K, LUSTIG M, et al. An interior-point method for large-scale L1-regularized least squares[J]. Journal of Selected Topics in Signal Processing, 2007, 1(4): 606-617. |
| [14] |
HAGER G D, BELHUMEUR P N. Efficient region tracking with parametric models of geometry and illumination[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(10): 1025-1039. DOI:10.1109/34.722606 |
| [15] |
KALAL Z, MATAS J, MIKOLAJCZYK K. P-N learning: Bootstrapping binary classifiers by structural constraints[C]//2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). San Francisco, CA: IEEE Computer Society, 2010: 49-56.
|
| [16] |
KALAL Z, MIKOLAJCZYK K, MATAS J. Tracking-learning-detection[J]. IEEE Transactions on, Pattern Analysis and Machine Intelligence, 2012, 34(7): 1409-1422. DOI:10.1109/TPAMI.2011.239 |
| [17] |
EVERINGHAM M, Van GOOL L, WILLIAMS C K I, et al. Thepascal visual object classes (voc) challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303-338. DOI:10.1007/s11263-009-0275-4 |