 2021, Vol. 53
2021, Vol. 53



2. 南京航空航天大学 民航学院, 南京 211106
2. College of Civil Aviation, Nanjing University of Aeronautics and Astronautics, Nanjing 211106, China
由于传感器成像特性的差异,红外传感器与可见光传感器拍摄的图像往往具有较强的互补性[1]。红外图像在低能见度条件下依然可以清晰的捕获目标,但是图像的边缘、纹理等细节不够丰富。可见光图像具有较强的细节保存能力,但是成像质量极易受到光照变化的影响。为了最大程度地结合两种图像类型的优点,将红外图像与可见光图像进行融合从而弥补传感器的固有缺陷成为了一条行之有效的思路。红外图像与可见光图像融合目前已广泛地应用于智能监控、目标监视、视频分析等领域[2]。
现有的图像融合算法根据所选取的融合信息可分为像素级、特征级、决策级3个层级,其中像素级图像融合直接对源图像进行融合,所保存的细节信息最为完备,因此在过去数十年中得到了广泛的关注[3]。像素级图像融合又可以进一步分为空间域融合与变换域融合两类,空间域融合无需对图像进行任何变换操作,因此实现较为简单,但是易于导致融合图像低对比度及块状分布等缺陷。为了克服上述不足,变换域图像融合采取的方案是对源图像进行适当的图像变换,并对转换后的图像信息进行融合。变换域图像融合的基本流程分为:1)图像变换,将源图像由空间域映射到变换域;2)活性度衡量,衡量变换后向量的重要程度;3)融合规则设计,采取恰当的融合规则完成活性层的筛选。显然,变换域图像融合的核心在于由空间域到变换域的变换方式[4]。
早期的变换域图像融合所采取的变换方法包括小波变换、金字塔变换等,通过人工构建的小波基与金字塔基实现源图像的变换。由于人工构建的图像变换的图像表示能力始终有限,该类方法始终难以获取图像中所有隐藏的信息。为克服早期图像变换的局限性,压缩感知(compressive sensing, CS)理论通过预训练的过完备字典实现源图像的变换,由于过完备字典是从大量的训练样本中学习得到的,CS理论的图像表示能力具有显著的优势,在过去10年中受到了广泛的研究[5]。基于CS理论的图像融合方法可分为3个步骤:首先将源图像分解为若干均等大小的图像块,对每一个图像块利用预训练的过完备字典计算与其对应的稀疏向量;其次,对同一位置对应的稀疏向量进行融合,获取融合后的向量;最后,利用融合后的向量结合过完备字典完成融合图像的重建。CS理论应用于图像融合最大的不足在于:1)基于图像块的建模方式破坏了源图像的语义结构,难以有效提取源图像中包含的空间上下文信息。2)基于图像块的建模、融合与重建对于两幅图像的匹配关系提出了严苛的要求,因此对于误匹配的容忍度较低[6]。为克服上述不足,近年来的相关研究工作开始尝试使用全局建模的方式对源图像进行变换,其中最为有效的变换方式为卷积神经网络(convolutional neural network, CNN)与卷积稀疏表示(convolutional sparse representation, CSR)。
CNN根据所需解决任务属性的不同可以分为分类式CNN与回归式CNN两类[7]。分类式CNN目前已在视觉目标检测、识别与分类等任务中得到了广泛应用,传统的视觉识别流程总体上可分为3个步骤,即特征表示、特征选取与特征分类,分类式CNN最大的优势在于通过多层卷积神经网络将上述3个步骤联合实现[8-12]。Liu等[4]指出,早期的变换域图像融合方法所包含的3个步骤与传统视觉识别的3个步骤具有极大的相似性,因此将分类式CNN应用于图像融合成为了一条可行的思路。回归式CNN又称为全卷积神经网络(fully convolutional neural network, FCN),一般采用端对端的方式实现视觉信息的分析与处理。回归式CNN目前已在低级视觉任务中得到了大量应用,例如图像分割、超分辨率重建等。因此,如果给定融合图像的真值图,即可训练回归式CNN通过端对端的方式获取融合结果。然而,无论是分类式CNN还是回归式CNN,其共性不足在于难以获取大量带标签的训练样本用于网络训练[13]。
CSR的基本思路源于Zeiler等[14]所设计的反卷积网络,其目的在于通过非监督的方式从自然图像中提取中级与高级特征。CSR的基本原理是通过一组预先训练的卷积字典滤波器将源图像分解为一系列卷积稀疏响应图,每一张卷积稀疏响应图都包含了目标不同层级的信息。作为一种非监督机器学习方法,CSR已被成功地用于解决许多视觉处理任务,例如目标跟踪、背景建模以及图像去噪等。在图像融合领域,CSR可以视为一种有效的图像变换方法[15]。由于CSR的图像建模方式无需对源图像进行分解,避免了基于稀疏表示(sparse representation, SR)的图像融合算法[3]的局部建模所带来的语义信息缺失与对误匹配的低容忍度两大缺陷,因此CSR已在图像融合领域得到了成功的应用。Zeiler等[14]指出,当基于CSR的反卷积网络的层数加深时,网络学习得到的图像特征将由边缘向整个目标转移,考虑到红外与可见光图像融合的初衷在于凸显源图像中的目标,为此本文设计了一种面向红外与可见光图像融合的多层卷积稀疏表示网络。
1 面向红外与可见光图像融合的多层卷积稀疏网络结构本文所设计的面向红外与可见光图像融合的多层卷积稀疏网络如图 1所示,该网络共包含5层,采用前馈的方式实现红外与可见光源图像的融合。

|
图 1 基于多层卷积稀疏表示的红外与可见光图像融合网络 Fig. 1 Multi-layer convolutional sparse representation-based network for infrared and visible image fusion |
网络的第1、2层为卷积稀疏层,通过预先训练的多层字典滤波器将源图像变换为一组卷积稀疏响应图。网络的第3层为融合层,通过对活性度衡量以获得卷积稀疏响应图的融合结果。网络的第4、5层为重建层,通过融合后的卷积稀疏响应图结合预先训练的多层字典滤波器实现融合图像的重建。
相比于SR、CSR、CNN等现有图像融合方法,本文所设计的图像融合网络具有以下优势:
1) 与SR的局部变换方式不同,本文所设计的图像融合网络采用全局变换的方式,有效抑制了SR应用于图像融合所导致的语义信息损失以及对细节信息的低容忍度两大缺陷。
2) 相比于基于CSR的图像融合方法,本文借鉴了卷积神经网络的设计思路。Papyan等[16]通过理论分析已经证明了多层卷积稀疏表示网络与CNN的结构存在着紧密的联系,多层卷积稀疏表示可以实现更有效的图像变换。
3) 区别于CNN的监督学习特性,本文所设计的多层卷积稀疏网络采取的学习方式是非监督的,无需大量带有标签的训练样本完成网络的训练,在实现上更为简单。
4) 本文算法的计算复杂度相比于SR具有明显的优势,相比于CSR不会明显上升。假设SR与CSR所使用的字典维度均为k,输入图像的大小均为D×D,基于SR的图像融合方法计算复杂度为O(D2×k2);基于CSR的图像融合方法计算复杂度为O(k×D×log(D)), 明显低于SR的计算复杂度[17];本文算法共包含两层卷积稀疏层,因此计算复杂度为O(2k×D×log(D)), 较CSR更高, 但依然低于SR。
2 基于多层卷积稀疏表示的红外与可见光图像融合算法 2.1 多层卷积稀疏表示理论给定输入图像I∈RA×B,以及一组相同大小的图像滤波器fi∈Ra×b, i=1, 2, …, m,这样一组滤波器被定义为卷积字典滤波器。CSR的基本思想在于任意一幅输入图像I都可以表示为卷积字典滤波器以及与之对应的卷积稀疏响应图si∈RA×B, i=1, 2, …, m乘积的和。CSR的目标函数如下式所示:
| $ \underset{\{s_i\}}{\arg \min } \frac{1}{2}\left\|\sum\limits_{i=1}^{m} \boldsymbol{f}_{i} * \boldsymbol{s}_{i}-\boldsymbol{I}\right\|_{2}^{2}+\lambda \sum\limits_{i=1}^{m}\left\|\boldsymbol{x}_{i}\right\|_{1} $ | (1) |
式中λ为稀疏正则项。
由于卷积稀疏响应S可被视为m张大小为A×B的图像集合,S中的每一张卷积稀疏响应图可以进一步地被另一个卷积字典滤波器F′∈Ra′×b′×m′和与之对应的卷积稀疏响应图表示,以此类推,可获得K层的卷积稀疏响应图。如定义1所示,这种类型的CSR被称为多层CSR。压缩感知理论的基本思想可视为通过对过完备字典D中原子的组合来表示输入信号,多层CSR的基本思想与压缩感知理论相似,但是区别于压缩感知理论所用到的字典原子,多层CSR用于表征信号的是采用多层字典的复杂组合Dl1Dl2…DlK,与压缩感知理论中的字典原子对应,这一类的字典组合被称为“分子”[16]。
定义1 给定输入图像I∈RA×B,对应与K层的卷积字典Dli={d1li, d2li, …, dlimi}, i=1, 2, …, K以及一组向量λ={λ1, λ2, …, λK}。多层CSR被定义为寻找一组对应于K层的卷积稀疏响应图Xli={x1li, x2li, …, xlimi}, i=1, 2, …, K。
layer 1:
layer 2:
……
layer K:
给定一幅输入图像和预先学习的多层字典滤波器,多层CSR的核心在于卷积稀疏响应图的估计。假设第p层的卷积字典滤波器为Dlp={d1lp, d2lp, …, dlpmp},则计算卷积稀疏响应图的目标函数如下式所示:
| $ \underset{\left\{\boldsymbol{x}_{i}^{l_{p}}\right\}}{\arg \min } \frac{1}{2}\left\|\sum\limits_{i=1}^{m_{p}} \boldsymbol{d}_{i}^{l_{p}} * \boldsymbol{x}_{i}^{l_{p}}-\boldsymbol{I}\right\|_{2}^{2}+\lambda_{p} \sum\limits_{i=1}^{m_{p}}\left\|\boldsymbol{x}_{i}^{l_{p}}\right\|_{1} $ | (2) |
式(2)可视为经典的基追踪问题的卷积形式,可通过交替方向乘子算法(Alternating direction method of multipliers, ADMM)有效求解。
为了引入ADMM求解式(2)的优化问题,将式(2)转换为如式(3)所示的交替形式,对式(3)的优化过程通过迭代的方式进行,从第t步至第t+1步的迭代如式(4)~式(6)所示:
| $ \begin{aligned} &\underset{\left\{\boldsymbol{x}_{i}^{l_{p}}\right\},\left\{y_{i}^{l_{p}}\right\}}{\arg \min } \frac{1}{2}\left\|\sum\limits_{i=1}^{m_{p}} \boldsymbol{d}_{i}^{l_{p}} * \boldsymbol{x}_{i}^{l_{p}}-\boldsymbol{I}\right\|_{2}^{2}+\lambda_{p} \sum\limits_{i=1}^{m_{p}}\left\|y_{i}^{l_{p}}\right\|_{1}\\ &{\rm{s.t.}} \quad \boldsymbol{x}_{i}^{l_{p}}-y_{i}^{l_{p}}=0 \end{aligned} $ | (3) |
| $ \begin{aligned} \left\{\boldsymbol{x}_{i}^{l_{p}}\right\}^{(t+1)}=& \underset{\left\{\boldsymbol{x}_{i}^{l_{p}}\right\}}{\arg \min } \frac{1}{2}\left\|\sum\limits_{i=1}^{m_{p}} \boldsymbol{d}_{i}^{l_{p}} * \boldsymbol{x}_{i}^{l_{p}}-\boldsymbol{I}\right\|_{2}^{2}+\\ & \frac{\rho}{2} \sum\limits_{i=1}^{m_{p}}\left\|\boldsymbol{x}_{i}^{l_{p}}-\boldsymbol{y}_{i}^{l_{p}(t)}+\boldsymbol{u}_{i}^{l_{p}(t)}\right\|_{2}^{2} \end{aligned} $ | (4) |
| $ \begin{array}{c} \left\{\boldsymbol{y}_{i}^{l_{p}}\right\}^{(t+1)}=\underset{\left\{\boldsymbol{y}_{i}^{l_{p}}\right\}}{\arg \min } \lambda_{p} \sum\limits_{i=1}^{m_{p}}\left\|\boldsymbol{y}_{i}\right\|_{1}+ \\ \frac{\rho}{2} \sum\limits_{i=1}^{m_{p}}\left\|\boldsymbol{x}_{i}^{l_{p}(t+1)}-\boldsymbol{y}_{i}^{l_{p}(t)}+\boldsymbol{u}_{i}^{l_{p}(t)}\right\|_{2}^{2} \end{array} $ | (5) |
| $ \boldsymbol{u}_{i}^{(t+1)}=\boldsymbol{u}_{i}^{(t)}+\boldsymbol{x}_{i}^{(t+1)}-\boldsymbol{y}_{i}^{(t+1)} $ | (6) |
式中u为引入的辅助变量。
对于式(5)的求解通过软阈值法即可完成,而对于式(4)的求解相对复杂,需进一步转换为如式(7)所示的形式。定义变量I, dilp, zilp和xilp在傅里叶频域对应的变量为Î,
| $ \underset{\left\{\boldsymbol{x}_{i}^{l_{p}}\right\}}{\arg \min }\frac{1}{2}\left\|\sum\limits_{i=1}^{m_{p}} \boldsymbol{d}_{i}^{l_{p}} * \boldsymbol{x}_{i}^{l_{p}}-\boldsymbol{I}\right\|_{2}^{2}+\frac{\rho}{2} \sum\limits_{i=1}^{m_{p}}\left\|\boldsymbol{x}_{i}^{l_{p}}-\boldsymbol{z}_{i}^{l_{p}}\right\|_{2}^{2} $ | (7) |
| $ \underset{\left\{\hat{\boldsymbol{x}}_{i}^{l_{p}}\right\}}{\arg \min } \frac{1}{2}\left\|\sum\limits_{i=1}^{m_{p}} \hat{\boldsymbol{d}}_{i}^{l_{p}} * \hat{\boldsymbol{x}}_{i}^{l_{p}}-\hat{\boldsymbol{I}}\right\|_{2}^{2}+\frac{\rho}{2} \sum\limits_{i=1}^{m_{p}}\left\|\hat{\boldsymbol{x}}_{i}^{l_{p}}-\hat{\boldsymbol{z}}_{i}^{l_{p}}\right\|_{2}^{2} $ | (8) |
定义
| $ \begin{aligned} &\hat{\boldsymbol{X}}^{l_{p}} =\left(\hat{\boldsymbol{x}}_{1}^{l_{p}}, \hat{\boldsymbol{x}}_{2}^{l_{p}}, \cdots, \hat{\boldsymbol{x}}_{m_{p}}^{l_{p}}\right) \\ &\hat{\boldsymbol{D}}^{l_{p}}=\left(\hat{\boldsymbol{d}}_{1}^{l_{p}}, \hat{\boldsymbol{d}}_{2}^{l_{p}}, \cdots, \hat{\boldsymbol{d}}_{m_{p}}^{l_{p}}\right) \\ &\hat{\boldsymbol{z}}^{l_{p}} =\left(\hat{\boldsymbol{z}}_{1}^{l_{p}}, \hat{\boldsymbol{z}}_{2}^{l_{p}}, \cdots, \hat{\boldsymbol{z}}_{m_{p}}^{l_{p}}\right) \end{aligned} $ | (9) |
| $ \underset{\hat{\boldsymbol{X}}^{l_{p}}}{\arg \min } \frac{1}{2}\left\|\hat{\boldsymbol{D}}^{l_{p}} \hat{\boldsymbol{X}}^{l_{p}}-\hat{\boldsymbol{I}}\right\|_{2}^{2}+\frac{\rho}{2}\|\hat{\boldsymbol{x}}-\hat{\boldsymbol{z}}\|_{2}^{2} $ | (10) |
| $ \left(\hat{\boldsymbol{D}}^{l_{p} H} \boldsymbol{D}^{l_{p}}+\rho \boldsymbol{E}\right) \hat{\boldsymbol{X}}^{l_{p}}=\hat{\boldsymbol{D}}^{l_{p} H} \hat{\boldsymbol{I}}+\rho \hat{\boldsymbol{z}}^{l_{p}} $ | (11) |
定义1中卷积字典需要用训练样本中学习获得,以第p层的卷积字典学习过程为例,假设用于学习的训练样本为一组图像Iilp∈RA×B, i=1, 2, …, up,则第p层字典学习的优化目标函数如下式所示:
| $ \begin{gathered} \underset{\left\{\boldsymbol{d}_{j}^{l_{p}}\right\}}{\arg}\underset{\left\{\boldsymbol{x}_{i, j}^{l_{p}}\right\}}{\min } \frac{1}{2} \sum\limits_{i=1}^{u_{p}}\left\|\sum\limits_{j=1}^{m_{p}} \boldsymbol{d}_{j}^{l_{p}} * \boldsymbol{x}_{i, j}^{l_{p}}-\boldsymbol{I}_{i}^{l_{p}}\right\|_{2}^{2}+ \\ \lambda_{p} \sum\limits_{i=1}^{u_{p}} \sum\limits_{j=1}^{m_{p}}\left\|\boldsymbol{x}_{i, j}^{l_{p}}\right\|_{1} \end{gathered} $ | (12) |
式中||djlp||1=1, j=1, 2, …, mp。
式(12)的优化可以拆分为对{xi, jlp}的优化以及对{djlp}的优化交替求解,对{xi, jlp}的优化及对{djlp}的优化如式(13)、(14)所示。式(13)中的字典{djlp}是固定的,针对{xi, jlp}的求解算法在多层卷积稀疏表示理论已经给出。因此,重点介绍式(14)的优化算法。
| $ \begin{gathered} \underset{\left\{\boldsymbol{x}_{i, j}^{l_{p}}\right\}}{\arg \min } \frac{1}{2} \sum\limits_{i=1}^{u_{p}}\left\|\sum\limits_{j=1}^{m_{p}} \boldsymbol{d}_{j}^{l_{p}} * \boldsymbol{x}_{i, j}^{l_{p}}-\boldsymbol{I}_{i}^{l_{p}}\right\|_{2}^{2}+ \\ \lambda_{p} \sum\limits_{i=1}^{u_{p}} \sum\limits_{j=1}^{m_{p}}\left\|\boldsymbol{x}_{i, j}^{l_{p}}\right\|_{1} \end{gathered} $ | (13) |
| $ \underset{\left\{\boldsymbol{d}_{j}^{l_{p}}\right\}}{\arg \min } \frac{1}{2} \sum\limits_{i=1}^{u_{p}}\left\|\sum\limits_{j=1}^{m_{p}} \boldsymbol{d}_{j}^{l_{p}} * \boldsymbol{x}_{i, j}^{l_{p}}-\boldsymbol{I}_{i}^{l_{p}}\right\|_{2}^{2} $ | (14) |
在式(14)中,卷积稀疏响应{xi, jlp}是固定的,该问题可以视为多方向法(Method of multiple directions, MOD)的卷积形式。为了快速实现卷积操作,采用傅里叶变换是一种有效的操作,当在离散傅里叶频域计算卷积时,需要对卷积字典{djlp}进行零填充操作从而匹配{xi, jlp}的维度。然而,空间域的零填充操作无法在离散傅里叶频域得到清晰的表示,为了解决该问题,本文采用分离变量的方式将式(14)改写为式(15),其中集合C和符号τ的定义如式(16)、(17)所示。通过求解式(15),卷积字典最终将以{PTdjlp}的形式获得,其中P为零元素填充运算符。
| $ \underset{\left\{\boldsymbol{d}_{j}^{l_{p}}\right\}}{\arg \min } \frac{1}{2} \sum\limits_{i=1}^{u_{p}}\left\|\sum\limits_{j=1}^{m_{p}} \boldsymbol{d}_{j}^{l_{p}} * \boldsymbol{x}_{i, j}^{l_{p}}-\boldsymbol{I}_{i}^{l_{p}}\right\|_{2}^{2}+\sum\limits_{j=1}^{m_{p}} \tau C\left(\boldsymbol{d}_{j}^{l_{p}}\right) $ | (15) |
| $ C=\left\{\boldsymbol{x} \in R^{A \times B}:\left(\boldsymbol{I}-P P^{\mathrm{T}}\right) \boldsymbol{x}=0,\|\boldsymbol{x}\|_{2}=1\right\} $ | (16) |
| $ \tau S(\boldsymbol{X})=\left\{\begin{array}{lll} 0 & \text { if } & \boldsymbol{X} \in \boldsymbol{S} \\ \infty & \text { if } & \boldsymbol{X} \notin \boldsymbol{S} \end{array}\right. $ | (17) |
通过引入辅助变量h以及参数ρ,式(15)可以改写为式(18)的形式从而采用ADMM求解,从第t步至第t+1步的迭代过程如式(19)~式(21)所示。
| $ \begin{aligned} &\underset{\left\{\boldsymbol{d}_{j}^{l_{p}}\right\}}{\arg}\underset{\left\{\boldsymbol{g}_{j}^{l_{p}}\right\}}{\min } \frac{1}{2} \sum\limits_{i=1}^{u_{p}}\left\|\sum\limits_{j=1}^{m_{p}} \boldsymbol{d}_{j}^{l_{p}} * \boldsymbol{x}_{i, j}^{l_{p}}-\boldsymbol{I}_{i}^{l_{p}}\right\|_{2}^{2}+\sum\limits_{j=1}^{m_{p}} \tau C\left(\boldsymbol{g}_{j}^{l_{p}}\right)\\ &{\rm{s.t. }}\ \ \forall j, \boldsymbol{d}_{j}^{l_{p}}-\boldsymbol{g}_{j}^{l_{p}}=0 \end{aligned} $ | (18) |
| $ \begin{aligned} \left\{\boldsymbol{d}_{j}^{l_{p}}\right\}^{(t+1)}=& \underset{\left\{{d}_{j}^{l_{p}}\right\}}{\arg \min } \frac{1}{2} \sum\limits_{i=1}^{u_{p}}\left\|\sum\limits_{j=1}^{m_{p}} \boldsymbol{d}_{j}^{l_{p}} * \boldsymbol{x}_{i, j}^{l_{p}}-\boldsymbol{I}_{i}^{l_{p}}\right\|_{2}^{2}+\\ & \frac{\rho}{2} \sum\limits_{j=1}^{m_{p}}\left\|\boldsymbol{d}_{j}^{l_{p}}-\boldsymbol{g}_{j}^{l_{p}(t)}+\boldsymbol{h}_{j}^{l_{(}(t)}\right\|_{2}^{2} \end{aligned} $ | (19) |
| $ \begin{aligned} &\left\{\boldsymbol{g}_{j}^{l_{p}}\right\}^{(t+1)}=\underset{\left\{\boldsymbol{g}_{j}^{l_{p}}\right\}}{\arg \min } \sum\limits_{j=1}^{m_{p}} \tau C\left(\boldsymbol{g}_{j}^{l_{p}}\right)+ \\ &\frac{\rho}{2} \sum\limits_{j=1}^{m_{p}}\left\|\boldsymbol{d}_{j}^{l_{p}(t+1)}-\boldsymbol{g}_{j}^{l_{p}}+\boldsymbol{h}_{j}^{l_{p}(t)}\right\|_{2}^{2} \end{aligned} $ | (20) |
| $ \boldsymbol{h}_{j}^{l_{p}(t+1)}=\boldsymbol{h}_{j}^{l_{p}(t)}+\boldsymbol{d}_{j}^{l_{p}(t+1)}-\boldsymbol{g}_{j}^{l_{p}(t+1)} $ | (21) |
对{gjlp}的优化通过软阈值法即可有效实现,然而对{djlp}的优化则相对复杂,需进一步转换为式(22)的形式。定义Iilp,djlp,xi, jlp的频域形式为Îilp,
| $ \begin{gathered} \underset{\left\{\boldsymbol{d}_{j}^{l_{p}}\right\}}{\arg \min } \frac{1}{2} \sum\limits_{i=1}^{u_{p}}\left\|\sum\limits_{j=1}^{m_{p}} \boldsymbol{d}_{j}^{l_{p}} * \boldsymbol{x}_{i, j}^{l_{p}}-\boldsymbol{I}_{i}^{l_{p}}\right\|_{2}^{2}+ \\ \frac{\rho}{2} \sum\limits_{j=1}^{m_{p}}\left\|\boldsymbol{d}_{j}^{l_{p}}-\boldsymbol{z}_{j}^{l_{p}}\right\|_{2}^{2} \end{gathered} $ | (22) |
| $ \begin{gathered} \underset{\left\{\hat{\boldsymbol{d}}{}_{j}^{l_{p}}\right\}}{\arg \min } \frac{1}{2} \sum\limits_{i=1}^{u_{p}}\left\|\sum\limits_{j=1}^{m_{p}} \hat{\boldsymbol{d}}_{j}^{l_{p}} * \hat{\boldsymbol{x}}_{i, j}^{l_{p}}-\hat{\boldsymbol{I}}_{i}^{l_{p}}\right\|_{2}^{2}+ \\ \frac{\rho}{2} \sum\limits_{j=1}^{m_{p}}\left\|\hat{\boldsymbol{d}}_{j}^{l_{p}}-\hat{\boldsymbol{z}}_{j}^{l_{p}}\right\|_{2}^{2} \end{gathered} $ | (23) |
定义
| $ \begin{aligned} &\hat{\boldsymbol{X}}_{i}^{l_{p}} =\left(\hat{\boldsymbol{x}}_{i, 1}^{l_{p}}, \hat{\boldsymbol{x}}_{i, 2}^{l_{p}}, \cdots, \hat{\boldsymbol{x}}_{i, m_{p}}^{l_{p}}\right) \\ &\hat{\boldsymbol{D}}^{l_{p}} =\left(\hat{\boldsymbol{d}}_{1}^{l_{p}}, \hat{\boldsymbol{d}}_{2}^{l_{p}}, \cdots, \hat{\boldsymbol{d}}_{m_{p}}^{l_{p}}\right) \\ &\hat{\boldsymbol{z}}^{l_{p}} =\left(\hat{\boldsymbol{z}}_{1}^{l_{p}}, \hat{\boldsymbol{z}}_{2}^{l_{p}}, \cdots, \hat{\boldsymbol{z}}_{m_{p}}^{l_{p}}\right) \end{aligned} $ | (24) |
| $ \underset{\hat{D}^{l_{p}}}{\arg \min } \frac{1}{2} \sum\limits_{i=1}^{u_{p}}\left\|\hat{\boldsymbol{X}}_{i}^{l_{p}} \hat{\boldsymbol{D}}^{l_{p}}-\hat{\boldsymbol{I}}_{i}^{l_{p}}\right\|_{2}^{2}+\frac{\rho}{2}\left\|\hat{\boldsymbol{D}}^{l_{p}}-\hat{\boldsymbol{z}}^{l_{p}}\right\|_{2}^{2} $ | (25) |
| $ \sum\limits_{i=1}^{u_{p}}\left(\hat{\boldsymbol{X}}_{i}^{l_p H} \hat{\boldsymbol{X}}_{i}^{l_{p}}+\rho \boldsymbol{E}\right) \hat{\boldsymbol{D}}^{l_{p}}=\sum\limits_{i=1}^{u_{p}} \hat{\boldsymbol{X}}_{i}^{l_{p} H} \hat{\boldsymbol{I}}_{i}^{l_{p}}+\rho \hat{\boldsymbol{z}}^{l_{p}} $ | (26) |
至此,多层卷积字典学习的定义归纳如下。
定义2 给定对应于K层的训练样本Iilp∈RAp×Bp, i=1, 2, …, up; p=1, 2, …, K和向量λ={λ1,λ2,…,λk}, 多层卷积字典学习的定义为寻找对应于K层的卷积字典Dli={d1li, d2li, …, dlimi}, i=1, 2, …, K。
layer1:
layer2:
……
layerK:
如图 1所示,给定一组配准后的红外图像IIN与可见光图像IVI,本文所设计的图像融合网络共包含5层,以前馈的方式实现。
在第1、2层的卷积稀疏层,给定对应于两层的预训练卷积字典Dl1={d1l1, d2l1, …, dl1m1},Dl2={d1l2, d2l2, …, dl2m2}和向量λ=[λ1, λ2],对应于两层的卷积稀疏响应可通过式(27)、(28)求解。
| $ \left\{\begin{array}{l} \underset{\left\{\boldsymbol{x}_{i}^{\mathrm{IN}l_{1}}\right\}}{\arg\min} \frac{1}{2}\left\|\sum\limits_{i=1}^{m_{1}} \boldsymbol{d}_{i}^{l_{1}} * \boldsymbol{x}_{i}^{\mathrm{IN}l_{1}}-\boldsymbol{I}^{\mathrm{IN}}\right\|_{2}^{2}+\lambda_{1} \sum\limits_{i=1}^{m_{1}}\left\|\boldsymbol{x}_{i}^{\mathrm{IN}_{1}}\right\|_{1} \\ \underset{\left\{\boldsymbol{x}_{i}^{\mathrm{VI}l_{1}}\right\}}{\arg\min} \frac{1}{2}\left\|\sum\limits_{i=1}^{m_{1}} \boldsymbol{d}_{i}^{l_{1}} * \boldsymbol{x}_{i}^{\mathrm{VI}l_{1}}-\boldsymbol{I}^{\mathrm{VI}}\right\|_{2}^{2}+\lambda_{1} \sum\limits_{i=1}^{m_{1}}\left\|\boldsymbol{x}_{i}^{\mathrm{VI}l_{1}}\right\|_{1} \end{array}\right. $ | (27) |
| $ \left\{\begin{array}{l} \underset{\left\{\boldsymbol{x}_{i}^{\mathrm{IN}l_{2}}\right\}}{\arg\min} \frac{1}{2}\left\|\sum\limits_{i=1}^{m_{2}} \boldsymbol{d}_{i}^{l_{2}} * \boldsymbol{x}_{i}^{\mathrm{IN}l_{2}}-\boldsymbol{x}_{i}^{\mathrm{IN}l_{1}}\right\|_{2}^{2}+\lambda_{2} \sum\limits_{i=1}^{m_{2}}\left\|\boldsymbol{x}_{i}^{\mathrm{IN}_{2}}\right\|_{2} \\ \underset{\left\{\boldsymbol{x}_{i}^{\mathrm{VI}l_{2}}\right\}}{\arg\min} \frac{1}{2}\left\|\sum\limits_{i=1}^{m_{2}} \boldsymbol{d}_{i}^{l_{2}} * \boldsymbol{x}_{i}^{\mathrm{VI}l_{2}}-\boldsymbol{x}_{i}^{\mathrm{VI}l_{1}}\right\|_{2}^{2}+\lambda_{2} \sum\limits_{i=1}^{m_{2}}\left\|\boldsymbol{x}_{i}^{\mathrm{VI}l_{2}}\right\|_{2} \end{array}\right. $ | (28) |
在此之后,如式(27)所示,通过l1最大绝对值融合规则来融合第2层卷积稀疏层输出的{xiINl2}和{xiVIl2}。其中Xl2=(x1l2, x2l2, …, xl2m1)和Xl2(a, b)表示Xl2在位置(a, b)处的元素值。
| $ \boldsymbol{X}^{{Fl}_{2}}(a, b)=\left\{\begin{array}{l} \boldsymbol{X}^{\mathrm{IN}l_{2}}(a, b)\left\|\boldsymbol{X}^{\mathrm{IN}l_{2}}(a, b)\right\|_{1}>\left\|\boldsymbol{X}^{\mathrm{VI}l_{2}}(a, b)\right\|_{1} \\ \boldsymbol{X}^{\mathrm{VI}l_{2}}(a, b)\left\|\boldsymbol{X}^{\mathrm{VI}l_{2}}(a, b)\right\|_{1}>\left\|\boldsymbol{X}^{\mathrm{IN}l_{2}}(a, b)\right\|_{1} \end{array}\right. $ | (29) |
最终,第4、5层的重建层利用预先训练的卷积字典逐层地重建恢复融合图像,第4层的重建过程如式(30)所示,第5层的重建过程如式(31)所示。
| $ \boldsymbol{x}_{i}^{F l_{1}} =\sum\limits_{i=1}^{m_{2}} \boldsymbol{d}_{i}^{l_{2}} * \boldsymbol{x}_{i}^{F l_{2}} $ | (30) |
| $ \boldsymbol{I}^{F} =\sum\limits_{i=1}^{m_{1}} \boldsymbol{d}_{i}^{l_{1}} * \boldsymbol{x}_{i}^{F l_{1}} $ | (31) |
至此,基于多层卷积稀疏网络的红外与可见光图像融合算法归纳如下。
| 表 |
如图 2所示,3组配准后的红外图像与可见光图像被选为实验用源图像。为了衡量图像融合的实验结果,本文采用主观评价与客观评价相结合的方式来评判融合结果的优劣。主观评价单纯依靠人眼衡量融合结果,而客观评价通过一系列图像质量的评价指标来衡量融合结果。本文所选取的图像质量评价指标包括空间频率(spatial frequency, SF),熵(Entropy,EN),互信息(mutual information, MI)以及梯度评价指标QAB/F,各项评价指标的含义如下:

|
图 2 实验图像 Fig. 2 Images used for experiment |
1) SF代表融合结果的清晰度与纹理丰富度,SF越高,融合效果越好。
2) EN代表融合结果包含的信息量与纹理,EN越高,融合效果越好。
3) MI代表融合结果的互信息,MI越高,融合效果越好。
4) QAB/F代表融合结果的梯度信息,QAB/F越高,融合效果越好。
3.2 参数学习与分析对于本文所设计的多层卷积稀疏表示网络而言,预训练的卷积稀疏字典对于网络的融合效果有着至关重要的影响,因此有必要针对字典的选取对网络融合效果的影响展开分析。由上一节的理论分析可知,给定训练样本,学习参数λ,迭代次数t,卷积字典的长度与卷积字典的大小对于卷积字典的学习有重要的影响。本文用于第1卷积稀疏层的训练样本为200幅自然图像,用于第2卷积稀疏层的训练样本为200幅卷积稀疏响应图,学习参数λ,迭代次数t设置为500。
3.2.1 卷积字典的尺寸对融合效果的影响如表 1所示,当第1、2卷积稀疏层的卷积字典长度固定为32时,卷积字典的大小取值为8×8,16×16,32×32和64×64。由于第2卷积稀疏层的卷积字典训练样本为卷积稀疏响应图而非自然图像,因此可以直观地看出Dl2比Dl1更稀疏。
| 表 1 不同尺寸的卷积字典 Tab. 1 Convolutional dictionaries with different sizes |








源图像1,2,3在不同尺寸字典下的图像融合客观评价指标如图 3~5所示。由图中结果可知,Dl1中字典尺寸变化带来的影响较Dl2更大,导致该现象的原因是:1)在字典训练的迭代次数一致的前提下,当字典的尺寸增大时,对于源图像变换的重建误差将随之上升,从而影响最终图像融合的效果;2)与卷积神经网络类似,浅层的网络对于提取图像的边缘信息更有效,且底层网络所提取的边缘信息是后续网络提取语义信息的基础,因此第1层的重建误差将传播至第2层,影响最终的图像融合结果。

|
图 3 源图像1在不同字典尺寸下融合结果的客观评价指标 Fig. 3 Objective assessment metrics for fusion results of image 1 with different dictionary sizes |

|
图 4 源图像2在不同字典尺寸下融合结果的客观评价指标 Fig. 4 Objective assessment metrics for fusion results of image 2 with different dictionary sizes |

|
图 5 源图像3在不同字典尺寸下融合结果的客观评价指标 Fig. 5 Objective assessment metrics for fusion results of image 3 with different dictionary sizes |
如表 2所示,当第1、2卷积稀疏层的卷积字典尺寸固定为16×16,卷积字典的长度为16,32,64和128。源图像1,2,3在不同尺寸字典下的图像融合客观评价指标如图 6~8所示。由图中结果可知,相比于卷积字典的尺寸,卷积字典的长度对融合结果的影响较小。当卷积字典的长度增加时,图像融合的效果会有微弱的改善,且Dl2对融合结果的影响较Dl1更大。上述现场产生的原因为:1)图像变换对于信息的表示能力极大地取决于特征的维度,而多层CSR的特征维度与字典的长度紧密相关,因此当字典长度增加时,融合效果会有相应的改善;2)与CNN的结构类似,从网络深层提取的信息相较于浅层信息的表示能力更强,因此Dl2对融合结果有更大的影响。
| 表 2 不同长度的卷积字典 Tab. 2 Convolutional dictionaries with different lengths |









|
图 6 源图像1在不同字典长度下融合结果的客观评价指标 Fig. 6 Objective assessment metrics for fusion results of image 1 with different dictionary lengths |

|
图 7 源图像2在不同字典长度下融合结果的客观评价指标 Fig. 7 Objective assessment metrics for fusion results of image 2 with different dictionary lengths |

|
图 8 源图像3在不同字典长度下融合结果的客观评价指标 Fig. 8 Objective assessment metrics for fusion results of image 3 with different dictionary lengths |
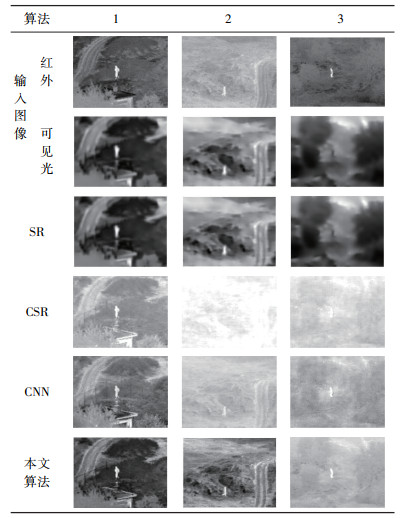
本文采用了3种经典的图像融合算法与本文设计的算法进行对比,3种对比算法分别是:基于稀疏表示(SR)的图像融合算法[3],基于卷积稀疏表示(CSR)的图像融合算法[15],基于卷积神经网络(CNN)的图像融合算法[9]。每一种融合算法所对应的融合结果刚见表 3,根据融合结果采用主观评价可知,本文所设计图像融合算法获得的结果在保留细节(例如可见光图像中的植被、建筑等)的同时显著增强了图像中的目标。
| 表 3 融合结果对比 Tab. 3 Comparison of fusion results |
进一步对本文所设计的算法进行客观评价,客观评价指标对比结果如图 9所示。由客观评价指标的计算结果分析可知,本文所提出的图像融合算法相比于同类算法具有一定的优势。

|
图 9 不同方法的融合结果客观评价指标对比 Fig. 9 Objective assessment metrics comparison of fusion results for different methods |
针对3组实验图像,对4种算法的实时性进一步进行验证分析。本文的算法实现平台为Matlab 2016b,计算机主频为3.4 GHz,内存为8 GB,采用Matlab的tic toc命令,对于4种算法的运行时间进行统计,统计结果见表 4。由表 4可知,本文算法相比于SR和CNN在计算时间方面具有明显的优势;相比于CSR,由于前馈式的网络结构导致需要进行两次卷积稀疏运算,因此计算时间略有增长。
| 表 4 融合计算时间对比 Tab. 4 Comparison of computation time for image fusion |
1) 本文设计了一种多层卷积稀疏表示网络,且给出了针对该网络的卷积稀疏字典训练方法与卷积稀疏响应图求解方法,作为一种有效的图像变换方法,该网络不仅可用于红外与可见光图像融合,同样可被扩展于目标检测、跟踪等领域。
2) 与基于稀疏表示的图像融合方法对比,本文所设计的多层卷积稀疏表示网络所具备的全局建模能力在误匹配条件下具有明显的优势。
3) 作为一种基于非监督学习的融合网络,本文所设计的图像融合方法无需大量带有标签的训练样本即可完成参数的学习,因此该网络同样可被用于解决其他类型的图像融合问题,例如多焦点图像融合、医学图像融合等。
| [1] |
MA Jiayi, MA Yong, LI Chang. Infrared and visible image fusion methods and applications: A survey[J]. Information Fusion, 2019, 45: 153. DOI:10.1016/j.inffus.2018.02.004 |
| [2] |
LI Shutao, KANG Xudong, FANG Leyuan, et al. Pixel-level image fusion: A survey of the state of the art[J]. Information Fusion, 2017, 33: 100. DOI:10.1016/j.inffus.2016.05.004 |
| [3] |
DING Meng, WEI Li, WANG Bangfeng. Research on fusion method for infrared and visible images via compressive sensing[J]. Infrared Physics & Technology, 2013, 57: 56. DOI:10.1016/j.infrared.2012.12.014 |
| [4] |
LIU Yu, CHEN Xun, WANG Zengfu, et al. Deep learning for pixel-level image fusion: Recent advances and future prospects[J]. Information Fusion, 2018, 42: 158. DOI:10.1016/j.inffus.2017.10.007 |
| [5] |
LIU Yu, LIU Shuping, WANG Zengfu. A general framework for image fusion based on multi-scale transform and sparse representation[J]. Information Fusion, 2015, 24: 147. DOI:10.1016/j.inffus.2014.09.004 |
| [6] |
ZHANG Qiang, LIU Yi, BLUM R S, et al. Sparse representation based multi-sensor image fusion for multi-focus and multi-modality images: A review[J]. Information Fusion, 2018, 40: 57. DOI:10.1016/j.inffus.2017.05.006 |
| [7] |
LIU Yu, CHEN Xun, PENG Hu, et al. Multi-focus image fusion with a deep convolutional neural network[J]. Information Fusion, 2017, 36: 191. DOI:10.1016/j.inffus.2016.12.001 |
| [8] |
LIU Y, CHEN X, CHENG J, et al. A medical image fusion method based on convolutional neural networks[C]//Proceedings of the 20th International Conference on Information Fusion (Fusion). Xi'an: IEEE, 2017: 1. DOI: 10.23919/ICIF.2017.8009769
|
| [9] |
LIU Yu, CHEN Xun, CHENG Juan, et al. Infrared and visible image fusion with convolutional neural networks[J]. International Journal of Wavelets, Multiresolution and Information Processing, 2018, 16(3): 1850018. DOI:10.1142/S0219691318500182 |
| [10] |
SUN Xudong, WU Pengcheng, HOI S C H. Face detection using deep learning: An improved faster RCNN approach[J]. Neurocomputing, 2018, 299: 42. DOI:10.1016/j.neucom.2018.03.030 |
| [11] |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: Unified, real-time object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 779. DOI: 10.1109/CVPR.2016.91
|
| [12] |
LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: Single shot multibox detector[C]//Proceedings of the European Conference on Computer Vision. Cham: Springer, 2016: 21. DOI: 10.1007/978-3-319-46448-0_2
|
| [13] |
KALANTARI N K, RAMAMOORTHI R. Deep high dynamic range imaging of dynamic scenes[J]. ACM Transactions on Graphics, 2017, 36(4): 1. DOI:10.1145/3072959.3073609 |
| [14] |
ZEILER M D, TAYLOR G W, FERGUS R. Adaptive deconvolutional networks for mid and high level feature learning[C]//Proceedings of the International Conference on Computer Vision. Barcelona: IEEE, 2011: 2018. DOI: 10.1109/ICCV.2011.6126474
|
| [15] |
LIU Yu, CHEN Xun, WARD R K, et al. Image fusion with convolutional sparse representation[J]. IEEE Signal Processing Letters, 2016, 23(12): 1882. |
| [16] |
PAPYAN V, ROMANO Y, ELAD M. Convolutional neural networks analyzed via convolutional sparse coding[J]. The Journal of Machine Learning Research, 2017, 18(1): 2887. |
| [17] |
HEIDE F, HEIDRICH W, WETZSTEIN G. Fast and flexible convolutional sparse coding[C]//Proceedings of the Computer Vision and Pattern Recognition. Boston, MA: IEEE, 2015. DOI: 10.1109/CVPR.2015.7299149
|